Chunked Margolus Neighborhoods
Falling sands performance
When we are thinking about how to optimize falling sands, we have 2 priorities: cache friendliness and parallelism.
The first is simpler, we place cells that are close together spatially close together in memory as well, which just means... arrays!
4096 element arrays (64x64 in 2d, 16x16x16 in 3d) seemed to be the sweet spot of linearization (2d/3d points -> index) performance and cache locality for modern hardware. Each of these arrays we call "chunks".
The simplest linearization scheme is taking strides for each dimension. For example, in 2D, if your chunk is 64x64 we would just use x + 64 * y. In 3d the equivalent (for 16x16x16) is z + 16 * x + 256 * y. You might notice something here though: The order of which dimensions matters. Z elements are placed right next to eachother in memory, while y elements are 256 elements apart. This is something we'll need to keep in mind for later.
Seeing this I started looking at different types of linearization since I was very optimistic about there being a more optimal layout for the memory. And lo-and-behold I come across Morton/Z-order encoding.
Unfortunately while we did become more optimal in spatial locality, calculating the index ends up having too much overhead. Even while using special instructions like pdep/pext (this doesn't seem to be true on GPUs though, more parallelization eliminates this overhead it seems). Or the CPU is doing some magical prefetching/pipelining. So back to the simple way we go for now.
If we want large grids we'll need to start looking at sparse voxel quad/octrees or my favorite variation: 64-trees (trees that are 4-ary instead of 2-ary, so you have 64 children instead of 8 per node, this gives you half the depth in the tree and improves cache locality when traversing).
So, now that we have our data laid out... how do we parallelize it?
Noita
Noita takes the approach of having 4 passes over chunks. Taking every other chunk in each direction so that there is a buffer zone of about 1/2 the size of a chunk that you can play around with on separate threads.
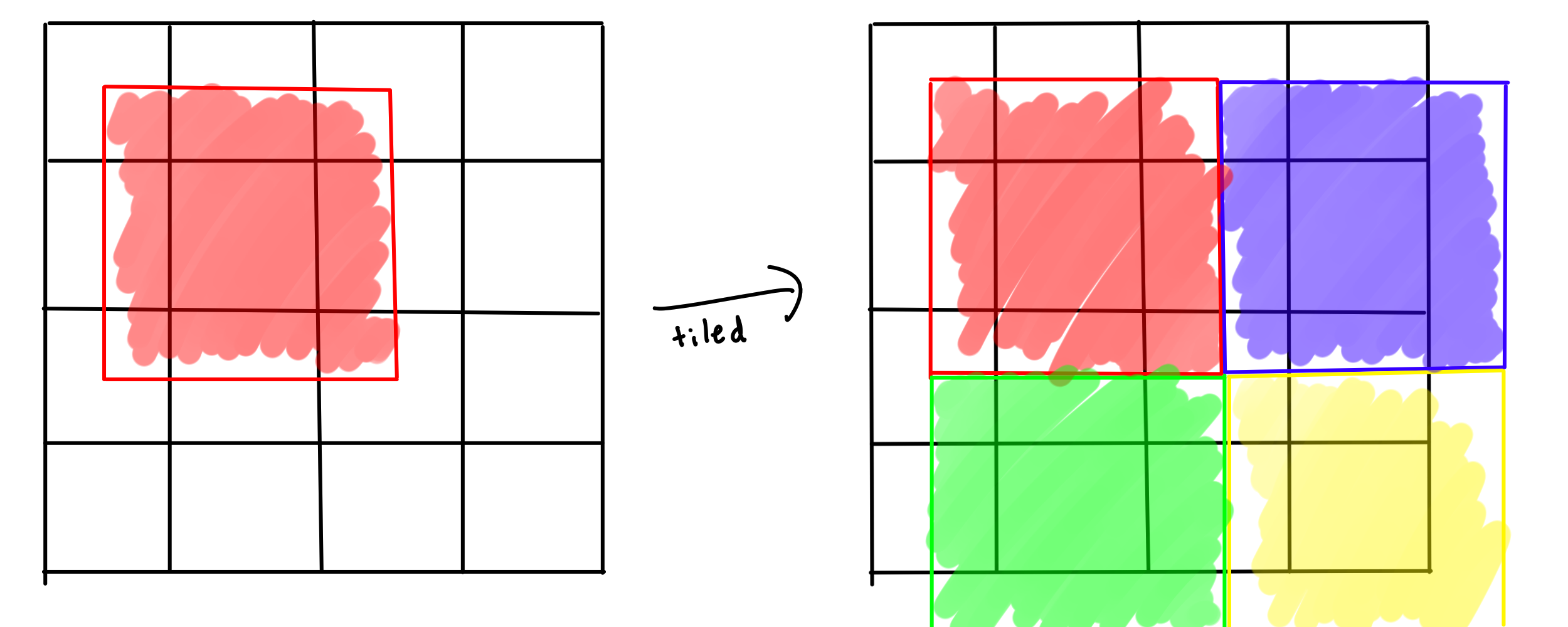
Next we move the area that we are processing over by 1 chunk in a Z pattern.
And we've done it! We can throw each of these chunks into a separate thread and not worry about aliasing the same data.
Atomic Compare-and-Swap
Atomic compare and swaps are another approach I've seen done on both the CPU and GPU. This is a non-deterministic and potentially lossy approach, but it gives more flexibility than other methods. This is something I'd recommend mainly for the GPU, otherwise you'll probably end up thrashing your cache with writes.
The non-determinism made it a non-starter for my project 1 , as I want to eventually network the simulation and having things desynchronize locally all the time makes latency and artifacts from eventual consistency much more noticeable.
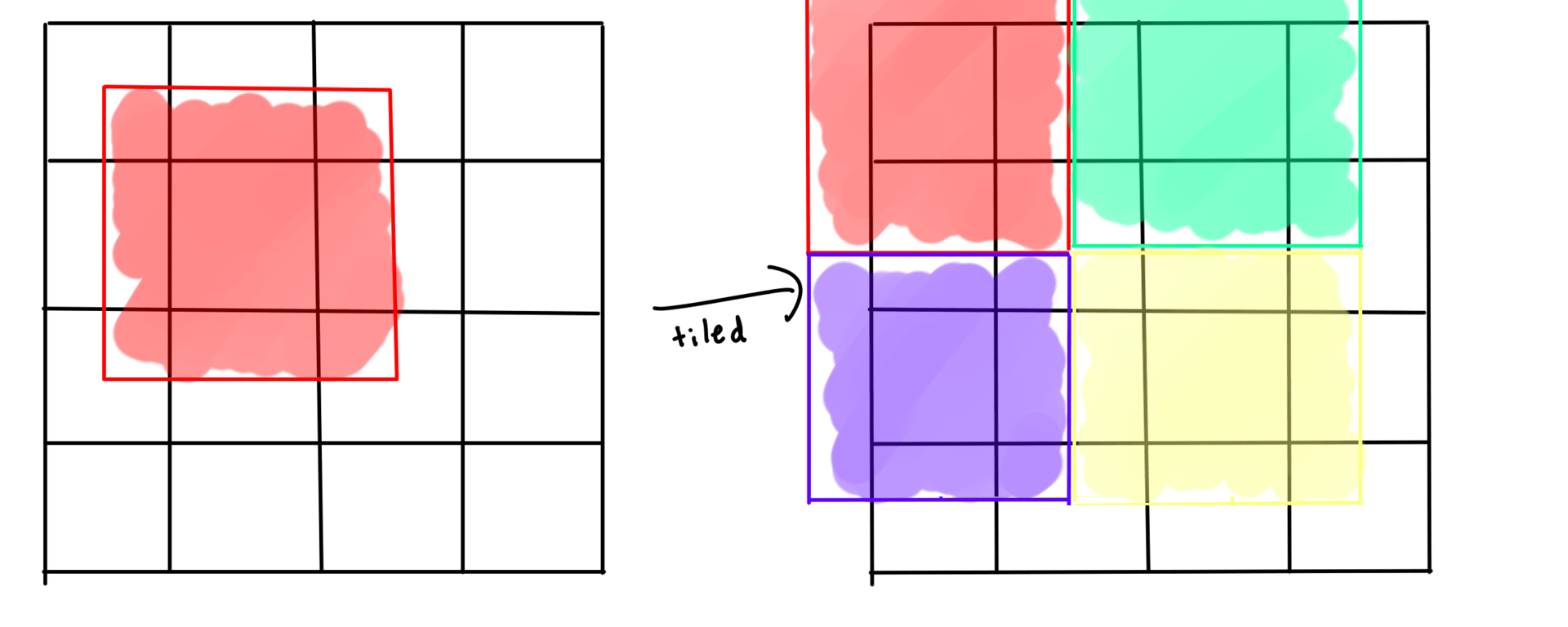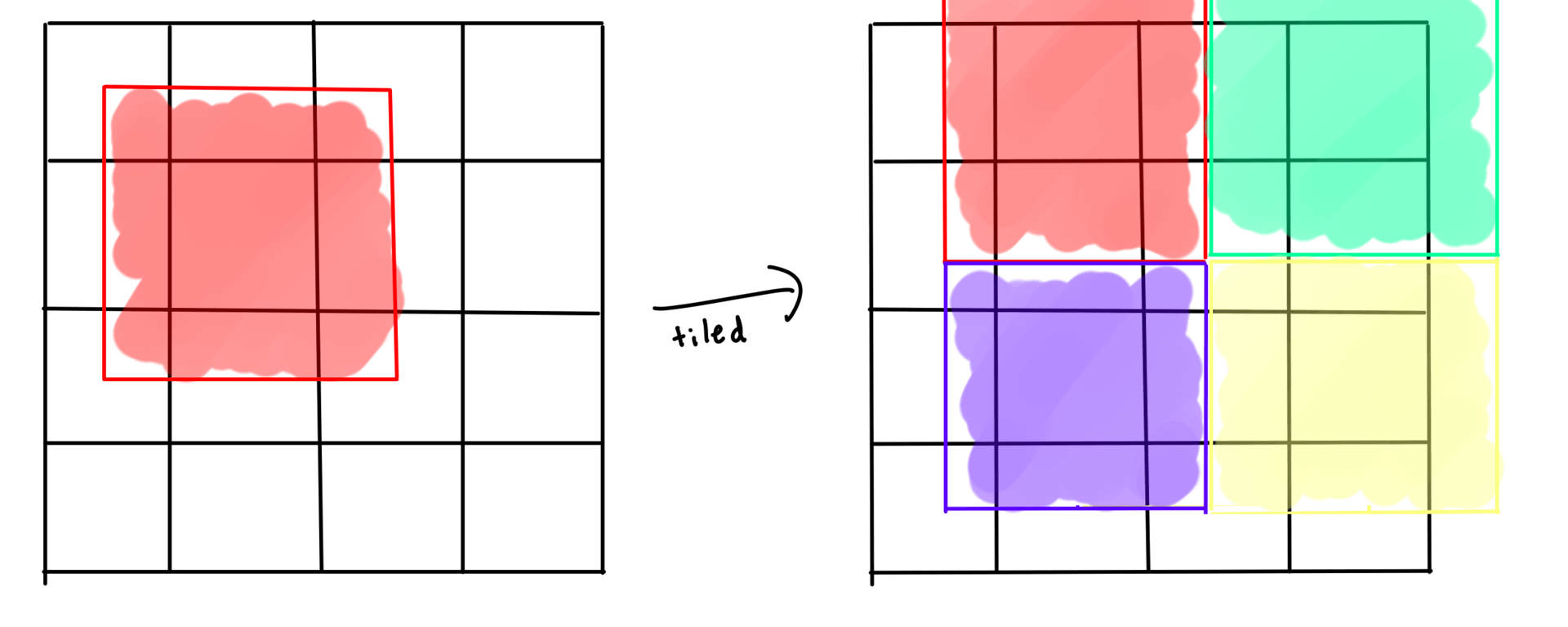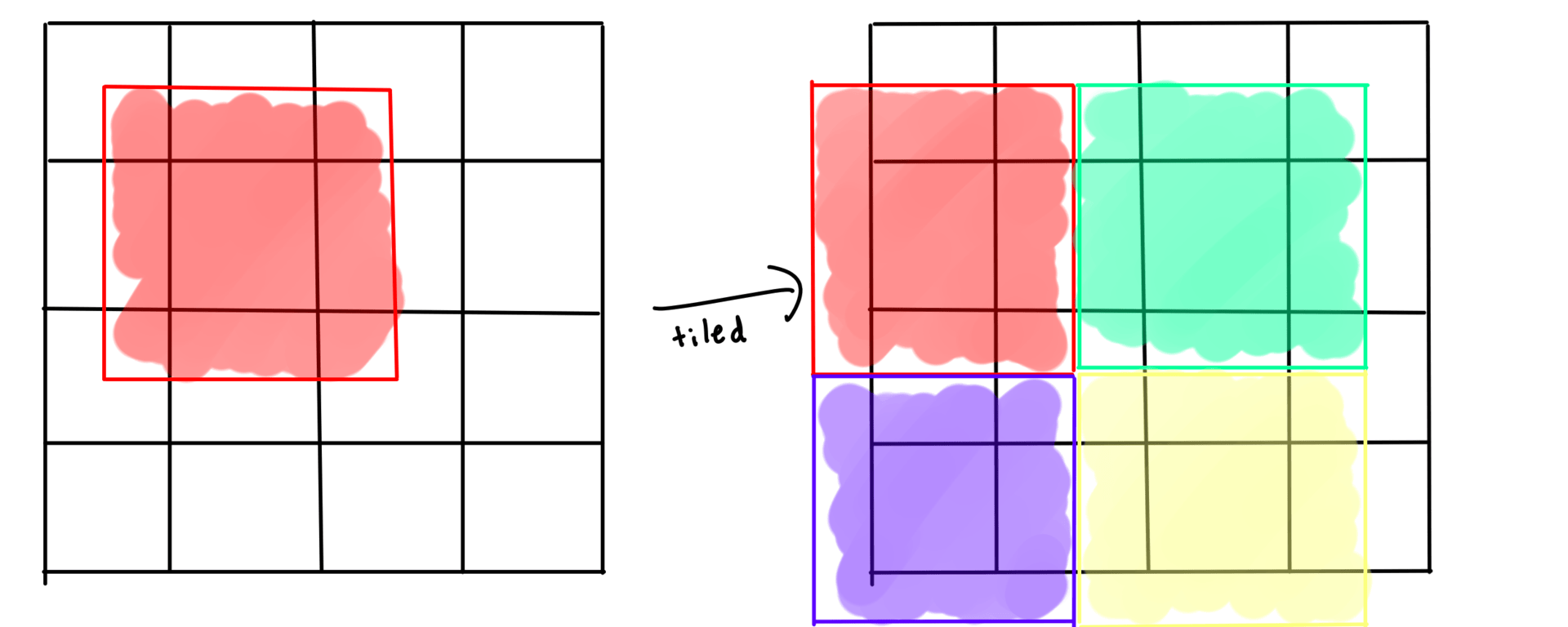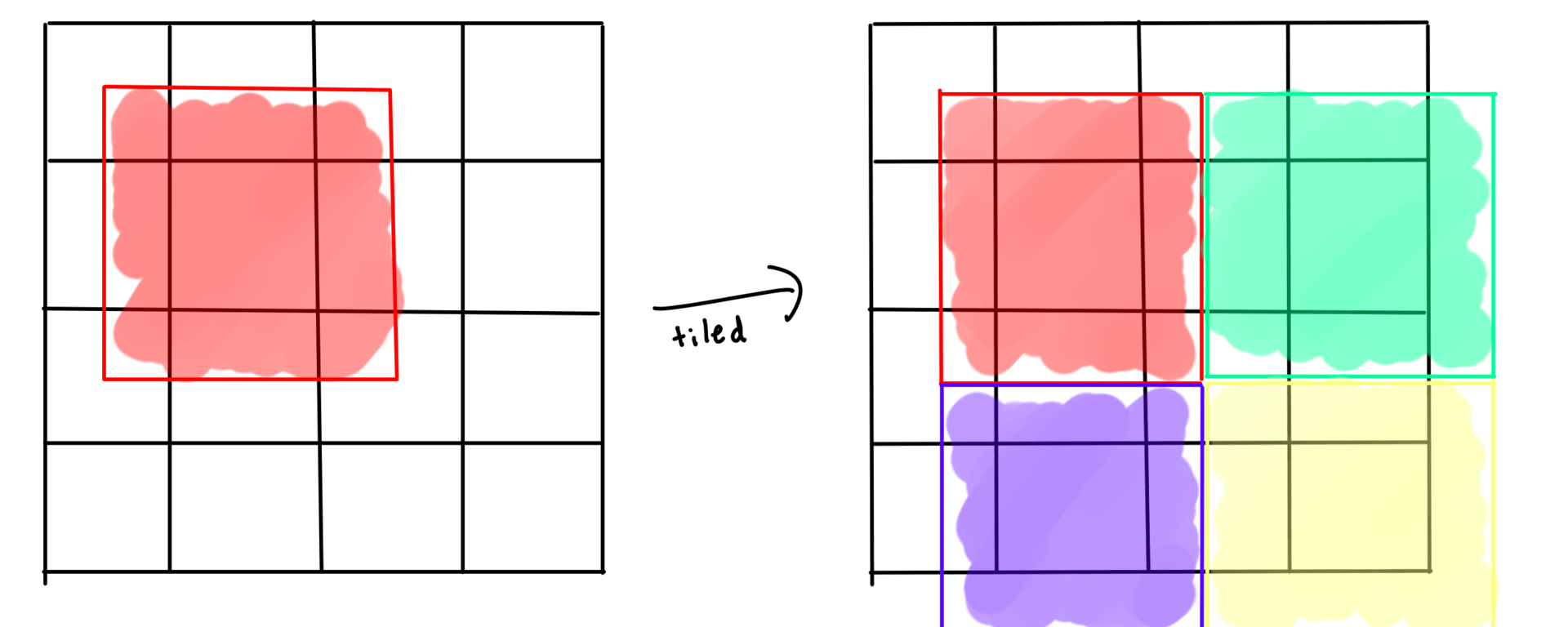
Chunked Margolus Neighborhoods
In this last approach we divide up the grid into a bunch of blocks and only allow each block to interact within itself. After one run you shift the blocks to overlap for the next run. This is called block cellular automata with the simplest method being margolus neighborhoods.
This sounds very similar to Noita's approach, so what's the difference?
Well, Noita only processes 1 out of 4 chunks at a time and then repeats the process again after a shift. Block cellular automata processes all chunks in a single pass, which helps with reducing the overhead of using something like work stealing since we don't need to wait for the last pass to finish up.
We run into a couple of issues with margolus neighborhoods fairly fast though:
- The artifacts from the boundaries of the blocks is very evident.
- CPUs caches hate this. When one core writes to a piece of memory, it will evict it from all other cores' caches, leading to cache misses everywhere.
How do we fix these issues? Scale it up! Instead of 2x2 blocks of cells, we do 2x2 blocks of chunks!
This means we aren't processing data in the same cacheline (64 bytes on modern CPUs) as other cores and boundaries of the blocks are less frequent/further apart.
The boundary artifacts will still exist, but are much less perceptible, you'll only notice it with fast movement getting a bit slowed down at chunk boundaries. But we have entirely fixed our problems with thrashing the cache.
TL;DR
- Atomics are an interesting solution that provides simplicity and flexibility in implementing cell types, but is non-deterministic and likely destroys the cache on the CPU.
- Noita's approach works very well, but might be sacrificing a bit of time waiting on each pass if only one or two chunks need to be processed. Fast moving cells will be slowed down much less than margolus neighborhoods.
- Margolus neighborhoods limit how you can implement cells and destroys your cache if used on a CPU. However these issues can be largely ignored by shifting the scale of the blocks to chunks rather than cells. Artifacts are more present here than Noita's approach, mainly because the buffer zone is only 1-2 voxels wide at the block boundaries, instead of 1/2 of a chunk's width.
Next steps
We have something that can fully utilize modern CPUs, scaling linearly with the amount of work, now we need to cut down on the amount of work we are doing in the first place.